|
|
|
|
Variation |
|
|
Mål |
|
Målet är att ge förståelse för variation och skilja på vad som beror på slumpen och vad som beror på speciella orsaker samt hur man hanterar de olika typerna av variation.
|
|
|
Repetition från Deming
Hänvisning |
|
Allting varierar. Variation betyder osäkerhet och förluster. Det finns två sorters variation, dels variation som beror på slumpen och kan förutsägas med statistiska metoder, och dels variation som uppträder av speciella (urskiljbara) orsaker och alltså inte kan förutsägas med statistiska metoder. Variation som beror på speciella orsaker kallas ofta systematisk variation. Spridning är ett annat namn för variation. Slumpmässig variation beror på ett antal faktorer. Dessa faktorer är systemberoende. Varje enskild faktors bidrag till variationen kan inte enkelt urskiljas utan man ser enbart faktorernas sammanlagda verkan. Ofta följer verkan av dessa faktorer en normalfördelning och utfallet kan därmed förutsägas med statistiska metoder. En process vars variation endast beror på slumpen och vars utfall kan förutsägas är en stabil process. Exempel på faktorer som bidrar till slumpmässig variation: Glapp, vibrationer, temperaturändringar, variationer i belysning, förändringar i råmaterial och processtider, tolkning av underlag, instruktioner och rutiner, medarbetare med olika erfarenhet och kunskap. Speciella orsaker,som ger upphov till systematisk variation, beror på t ex att fel uppstått, byte av råmaterial, ny personal, mm. Dessa orsaker till variation kan normalt inte förutsägas, men när de uppstått går det att finna källan till variationen. Dessa två typer av variation måste hanteras på helt olika sätt. Detta innebär att man gör ont värre om man inte har klart för sig vilken typ av variation man har att hantera. Gränsdragningen mellan slumpmässig och systematisk variation är svår och förutsätter kunskaper om både variation och den aktuella processen. Vad händer om man gör en felaktig bedömning av orsakerna till variation?
|
|
|
Några begrepp |
|
Vid insamling av data finns det några vanligt förekommande begrepp. En population består av ett antal objekt eller observationer (mätvärden) som har något gemensamt. Ett stickprov (sample) är t ex mätvärden från en del av en population. Hur mätvärdena i en population fördelar sig kan beskrivas med deras medelvärde och standardavvikelse (spridning).
|
|
|
Länk |
|
Kurs i statistik. HyperStat från Rice Virtual Lab vid Rice University, Houston. Kursen fungerar även bra som uppslagsbok för statistiska grundbegrepp.
|
|
|
Förutsättningar för att göra en statistisk bearbetning |
|
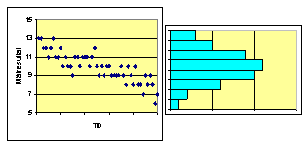
Observera för att det ska vara meningsfullt att beräkna medelvärde och standardavvikelse för ett material måste det vara normalfördelat. Detsamma gäller för andra statistiska metoder som t ex chi-två. Duglighetsberäkningar, som vi ska se senare, kräver också normalfördelat material. Det finns metoder för ej normalfördelat material, men de ligger utanför den här kursen. Nedan visas ett exempel på att histogrammet till höger ser ut som om materialet är normalfördelat, men av tidsdiagrammet till vänster framgår att här sker en förskjutning i tiden. |
|
|
|
|
Fritt
från Deming, Out of the Crisis.
|
|
|
"Det finns saker som man måste
vara fackman för att inte förstå." |
|
Här finns en systematisk förändring över tiden och detta innebär att materialet inte är i statistisk jämvikt, d.v.s. processen är inte stabil. Denna information framgår inte av histogrammet till höger. För att kunna bedöma ett material är det alltså bra att rita ett diagram som visar förändringarna över tiden.
|
|
|
Normalfördelning
|
|
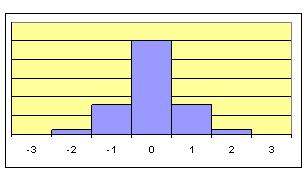
Figuren visar ett förenklat histogram för ett normalfördelat material. Vi har kontrollerat över tiden och inte funnit några systematiska förändringar.
|
|
|
|
|
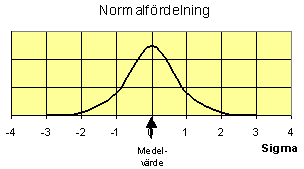
Om vi nu ökar antalet staplar (fler observationer och mindre klassbredd) och sammanbinder topparna på dem så får vi kurvan i figuren nedan. Detta är normalfördelningen.
|
|
|
|
|
|
|
|
|
|
Det är två parametrar som karakteriserar en normalfördelning
Ett sätt att bestämma medelvärde och standardavvikelse är att lägga in materialet i Excel och beräkna enligt
|
|
|
|
|
Trevliga exempel på statistik och fördelningar och experiment med fördelningar.
|
|
|
Funnel, ett försök att manipulera slumpen |
|
Vad händer om man försöker "förbättra" en
process vars variation endast beror på slumpen?
|
|
|
LSN 2003 |
|
|
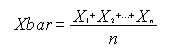
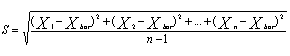
![]()